如何使用开源组件解决web应用中的XSS漏洞
本文包含以下内容:
- XSS概述
- XSS的防御原则
- 开源组件的使用
XSS(跨站脚本攻击)漏洞是Web应用程序中最常见的漏洞之一,它指的是恶意攻击者往Web页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web里面的html代码会被执行,从而达到恶意攻击用户的特殊目的,比如获取用户的cookie,导航到恶意网站,携带木马等。根据其触发方式的不同,可以分为反射型XSS、存储型XSS和DOM-base型XSS。漏洞“注入理论”认为,所有的可输入参数,都是不可信任的。通常我们说的不可信任的数据是指来源于HTTP客户端请求的URL参数、form表单、Headers以及Cookies等,但是,与HTTP客户端请求相对应的,来源于数据库、WebServices、其他的应用接口数据也同样是不可信的,这即是反射型XSS与存储型XSS的本质区别。
一般来说,我们可以通过XSS漏洞的表现形式来区分漏洞是反射型、存储型、DOM-base三种中的哪一种类型。
- 反射型XSS是指通过给别人发送带有恶意脚本代码参数的URL,当URL地址被打开时,带有恶意代码参数被HTML解析、执行。它的特点是非持久化,必须用户点击带有特定参数的链接才能引起。它的连接形式通常如下:
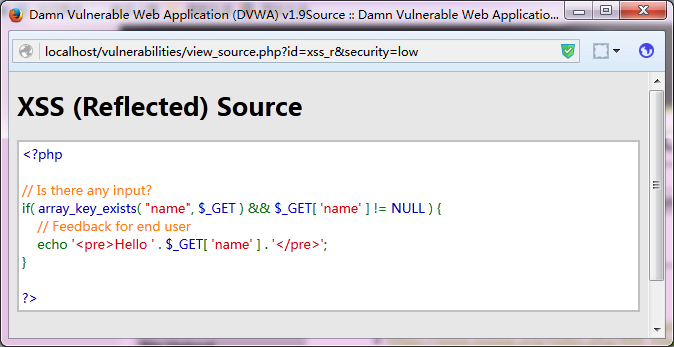
其name参数的值为http://localhost/vulnerabilities/xss_r/?name=%3Cscript%3Ealert%281%29%3B%3C%2Fscript%3E<script>alert(1);</script>,这样的参数值进入程序代码后未做任何处理,从而被执行。其代码如下图:
- 存储型XSS是指恶意脚本代码被存储进数据库,当其他用户正常浏览网页时,站点从数据库中读取了非法用户存储的非法数据,导致恶意脚本代码被执行。通常代码结构如下图:
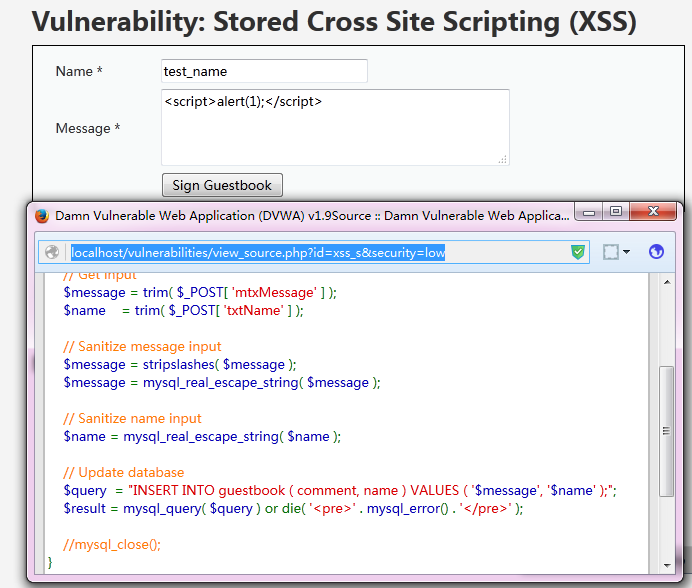
其发生XSS的根本原因是服务器端对写入数据库中的内容未做javascript脚本过滤。 - DOM-base型XSS是指在前端页面进行DOM操作时,带有恶意代码的片段被HTML解析、执行,从而导致XSS漏洞。
无论是哪种类型的XSS漏洞,其解析完成后,漏洞利用的代码基本雷同的。在日常工作中,常见的XSS漏洞Exploit攻击点有:
- 恶意js的引用

- Img标签(以img为例,下同)

- 大小写绕过安全检测

- 破坏原始标签结构

- 基于标签事件触发

- fromCharCode编码绕过

- javascript 转码

- HTML转码

- 混合型

- CSS文本

- CSS属性值

基于XSS上面所述的特性,在XSS的频发代码中,我们通常遵循以下处理规则:
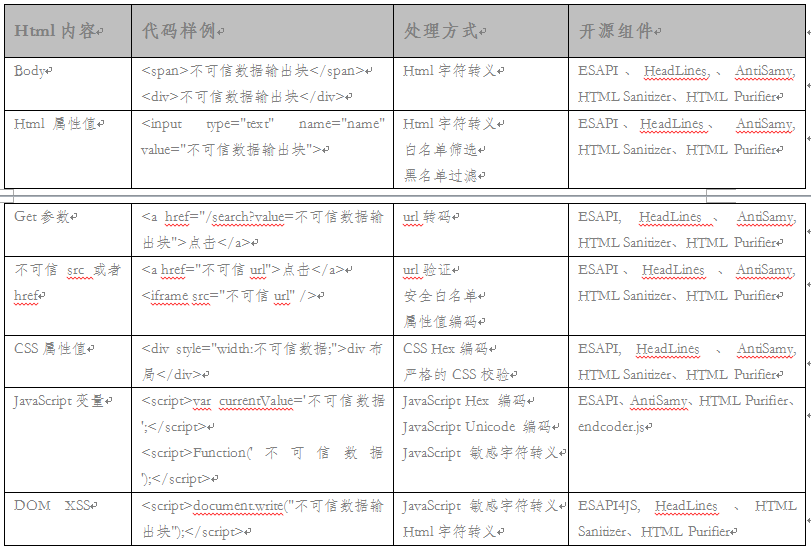
从上表中我们可以看出,ESAPI、HeadLines、AntiSamy、HTML Sanitizer 是开源组件中防御功能比较全面的4个,其中ESAPI、HeadLines除了对XSS具有很好的防御能力外,还对OWASP TOP 10中其他的安全漏洞都具有规范处理的能力。在单纯性地讨论其对XSS的防御能力时,我们需要看具体的应用场景或者需求点。如果仅仅是对客户端提交的简单的请求参数(通常指form表单域,不包含复杂文本和可编辑文本)做安全过滤,则HTML Sanitizer、Java Encoder都可以作为首选解决方案;如果不但对客户端提交的简单的请求参数做安全处理,而且,应用中会涉及复杂文本,类似于BBCode文本之类的数据处理,通常会首选AntiSamy作为解决方案;如果除了以上两点外,还需要做同源策略安全、Http Header安全、Cookies安全,则通常会首选HeadLines作为解决方案;如果还有更多层次的用户安全、Session会话安全、口令或随机数安全等,则ESAPI和Apache Shiro将会被考虑。那么,具体到某个软件项目中,是如何使用开源组件对XSS漏洞进行防护的呢?下面就以Java语言为例,对处理过程做简要的阐述。
第一步:确定使用的开源组件
首选是确定使用的开源组件,只有开源组件确定下来,才能确定解决方案的细节部分。在选择开源组件之前,要理解业务涉及的需求点,以免遗漏。一般来说,简单文本参数使用HTML Sanitizer,复杂文本参数使用AntiSamy。
第二步:定义安全过滤器
针对于XSS的处理,常用的解决办法是使用过滤器(Filter),由Filter中的doFilter方法对参数的内容进行安全过滤操作。其代码核心结构如图所示:

第三步:处理XSS
编写处理XSS函数clearXSS时,我们会根据所选择的开源组件不同而编写方式有所不同。当我们把开源组件的jar和依赖库添加到项目中之后,主要的工作是对此函数功能的实现,实现的基本思路是:从Request对象中获取请求的参数和http消息头,遍历每一个参数,如果某个参数值存在XSS,则对该值进行处理(过滤、编码、转义、拦截等),处理完毕后再重新赋值。 如果使用HTML Sanitizer,你的核心代码可能是

或者使用了Java Encoder,代码类似:

如果使用了AntiSamy,代码或许类似于
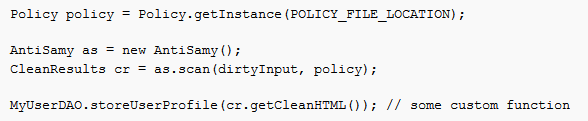
在HTML Sanitizer和AntiSamy中,我们都看到一个词:Policy,Policy即XSS防护策略,是指在XSS的文本进行处理时,按照怎么的规则去处理数据块:哪些html标签或属性是允许存在的,哪些的需要转义的,哪些是需要进行格式校验的,哪些是需要移除的等,这些都是在策略文件里去定义的。 HTML Sanitizer组件中,包含5个预定义的策略,具体在使用中,我们可以根据自己的需求选择某个策略。这5个策略的内容分别是:
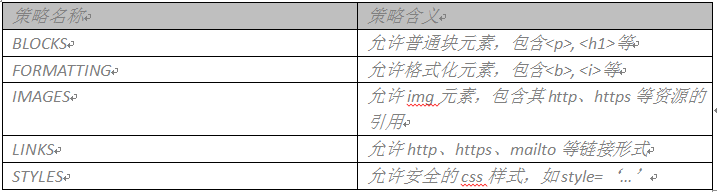
AntiSamy组件中对策略的定义相对复杂些,是由配置文件中多个选项指定的。其配置如图所示:
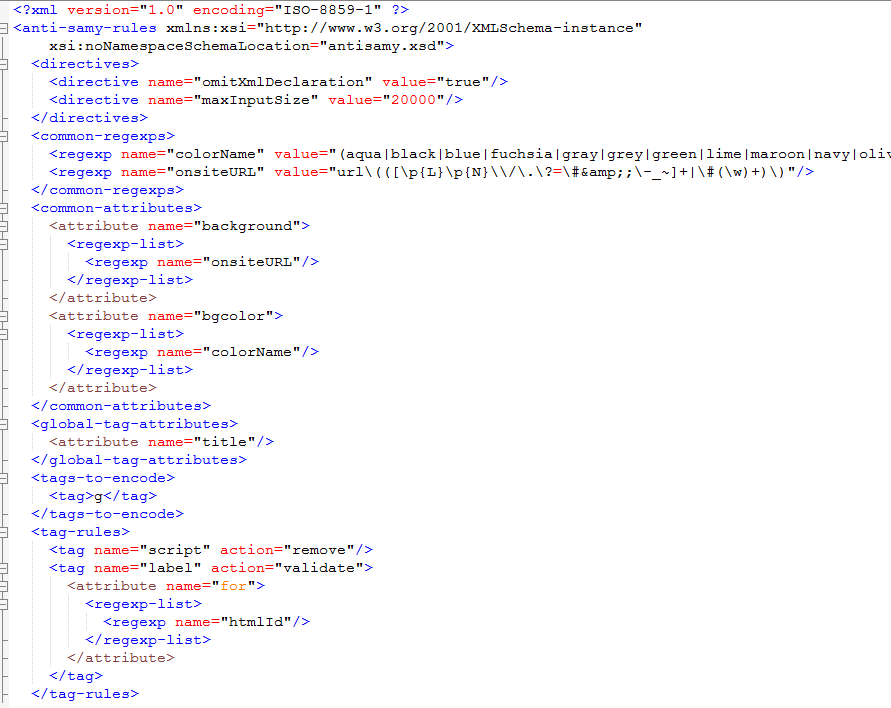
AntiSamy的策略配置是由规则(tag-rule、css-rule)来控制Antisamy对html标签(tag)、属性(attribute)中不可信数据做怎样的操作行为(action),其中操作行为可分为校验(validate)、过滤(filter)、清空(truncate)、移除(remove)。根据定义的操作行为,可以对不可信数据进行移除、清空、过滤和校验操作。当对不可信数据进行校验时,比如input标签,我们可以校验align属性值指定枚举值范围为left,right,top,middle,bottom,也可以校验value值是否匹配既定义的正则表达式,如图中common-regexps和common-attributes节点所示。Antisamy依据策略文件的具体配置,对传入的不可信数据,按照定义的规则对数据进行处理,最终返回可信的文本,即代码段中的cr.getClearHTML函数的返回值。当原来的不可信数据,经过处理变成可信数据,我们防护XSS的目的也就达到了。与HTML Sanitizer类似的是,AntiSamy除了默认的antisamy.xml外,也提供5个策略模板文件:antisamy-anythinggoes.xml、antisamy-ebay.xml、antisamy-myspace.xml、antisamy-slashdot.xml、antisamy-tinymce.xml。其中ebay的模板文件使用广泛,在实际项目中,可以直接使用此策略模板或者在其基础上修改即可。
第四步:添加http响应头XSS防护
完成clearXSS函数之后名,我们需要对http响应头添加XSS防护策略。通过clearXSS函数调用是在服务器层对XSS做防护,而添加http响应头XSS防护策略是从客户端浏览器层面防护XSS。常用的参数有:
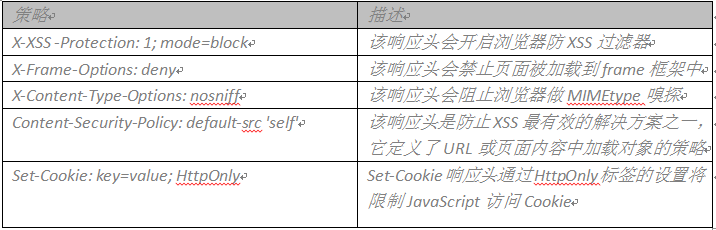
其核心代码大体如下:

第五步:启用安全过滤器
完成安全过滤器对不可信数据处理的编码逻辑之后,我们需要启用它。启用的过程即配置的过程,目的是使安全过滤器生效,这需要在web.xml中配置,并对所有请求进行拦截,其基本配置如下:

通过以上步骤的处理, web应用中因前端输入导致的XSS数据基本得以解决,但在实际的项目中,发生XSS的点可能各不相同,不是仅仅用一个安全过滤器进行全局拦截处理即可托付全盘那么简单。例如通过文件导入引发的XSS漏洞,则需要单独编码,调用开源组件对XSS进行防护。总之,无论是XSS漏洞还是其他的漏洞,安全防护是一个动态的概念,在进行XSS防护过程中,我们需要根据实际情况,不断地调整处理策略(Policy),以达到既能满足安全需要,正确处理非法的、不安全的数据,又能满足业务需要,不会错误拦截或处理了正常业务数据的最终目标。